Differential abundance analysis in python with milopy
Author: Emma Dann
Date: 27/08/2021
In this notebook I will demonstrate how to run differential abundance analysis on single-cell datasets using the python implementation of the Milo framework.
%load_ext autoreload
%autoreload 2
import numpy as np
import pandas as pd
import scanpy as sc
import scvelo ## For mouse gastrulation data
import anndata
import matplotlib.pyplot as plt
plt.rcParams['figure.figsize']=(8,8) #rescale figures
sc.settings.verbosity = 3
import milopy.core as milo
import milopy.plot as milopl
---------------------------------------------------------------------------
ModuleNotFoundError Traceback (most recent call last)
/tmp/ipykernel_209/3650979501.py in <module>
----> 1 import numpy as np
2 import pandas as pd
3 import scanpy as sc
4 import scvelo ## For mouse gastrulation data
5 import anndata
ModuleNotFoundError: No module named 'numpy'
Load and prepare example dataset
For this vignette I will use the mouse gastrulation data from Pijuan-Sala et al. 2019. The dataset can be downloaded as a anndata object from the scvelo package (v0.2.4).
adata = scvelo.datasets.gastrulation()
adata
AnnData object with n_obs × n_vars = 89267 × 53801
obs: 'barcode', 'sample', 'stage', 'sequencing.batch', 'theiler', 'doub.density', 'doublet', 'cluster', 'cluster.sub', 'cluster.stage', 'cluster.theiler', 'stripped', 'celltype', 'colour', 'umapX', 'umapY', 'haem_gephiX', 'haem_gephiY', 'haem_subclust', 'endo_gephiX', 'endo_gephiY', 'endo_trajectoryName', 'endo_trajectoryDPT', 'endo_gutX', 'endo_gutY', 'endo_gutDPT', 'endo_gutCluster', 'cell_velocyto_loom'
var: 'Accession', 'Chromosome', 'End', 'Start', 'Strand'
obsm: 'X_pca', 'X_umap'
layers: 'spliced', 'unspliced'
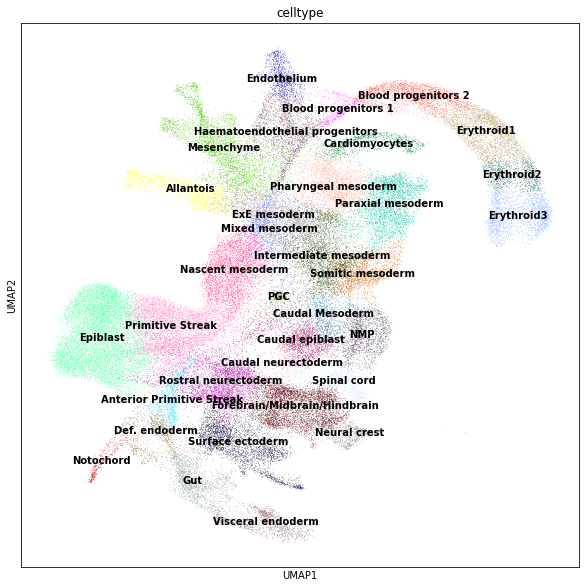
We will use this dataset to identify for cell populations that increase with time (i.e. embryonic stage)
sc.pl.umap(adata, color=["celltype"], legend_loc="on data");
sc.pl.umap(adata, color=["stage"]);

Build KNN graph
This object already contains PCA dimensionality reduction in adata.obsm["X_pca"]. We can use scanpy functions to build a KNN graph. We set the dimensionality and value for k to use in subsequent steps.
d = 30
k = 50
sc.pp.neighbors(adata, n_neighbors=k, n_pcs=d)
computing neighbors
using 'X_pca' with n_pcs = 30
finished: added to `.uns['neighbors']`
`.obsp['distances']`, distances for each pair of neighbors
`.obsp['connectivities']`, weighted adjacency matrix (0:01:06)
Construct neighbourhoods
This step assigns cells to a set of representative neighbourhoods on the KNN graph.
milo.make_nhoods(adata, prop=0.1)
WARNING:root:Using X_pca as default embedding
The assignment of cells to neighbourhoods is stored as a sparse binary matrix in adata.obsm. Here we see that cells have been assigned to 4970 neighbourhoods.
adata.obsm["nhoods"]
<89267x4970 sparse matrix of type '<class 'numpy.float32'>'
with 485371 stored elements in Compressed Sparse Row format>
The information on which cells are sampled as index cells of representative neighbourhoods is stored in adata.obs, along with the distance of the index to the kth nearest neighbor, which is used later for the SpatialFDR correction.
adata[adata.obs['nhood_ixs_refined'] != 0].obs[['nhood_ixs_refined', 'nhood_kth_distance']]
| nhood_ixs_refined | nhood_kth_distance | |
|---|---|---|
| index | ||
| cell_42 | 1 | 7.738092 |
| cell_230 | 1 | 7.720909 |
| cell_268 | 1 | 8.125346 |
| cell_401 | 1 | 8.443908 |
| cell_403 | 1 | 10.581521 |
| ... | ... | ... |
| cell_139212 | 1 | 6.854442 |
| cell_139272 | 1 | 7.441633 |
| cell_139296 | 1 | 8.785832 |
| cell_139297 | 1 | 4.096834 |
| cell_139304 | 1 | 8.789676 |
4970 rows × 2 columns
We can visualize the distribution of neighbourhood sizes to get an idea of the right value for k
nhood_size = np.array(adata.obsm["nhoods"].sum(0)).ravel()
plt.hist(nhood_size, bins=100);

Since here cells come from 34 samples, we want the average number of cells in a neighbourhood to peak around 34 x 3 = 102 cells, to have a median number of 3 cells per sample per neighbourhood.
Count cells in neighbourhoods
Milo leverages the variation in cell numbers between replicates for the same experimental condition to test for differential abundance. Therefore we have to count how many cells from each sample are in each neighbourhood. We need to use the cell metadata saved in adata.obs and specify which column contains the sample information.
milo.count_nhoods(adata, sample_col="sample")
This function adds adata.uns["nhood_adata"], that stores an anndata object where obs correspond to neighbourhoods and vars correspond to samples, and where .X stores the number of cells from each sample counted in a neighbourhood. This count matrix will be used for DA testing.
adata.uns["nhood_adata"]
AnnData object with n_obs × n_vars = 4970 × 34
obs: 'index_cell', 'kth_distance'
uns: 'sample_col'
Differential abundance testing with GLM
We are now ready to test for differential abundance in time. The experimental design needs to be specified with R-style formulas. In this case we need to convert the “stage” to a continuous variable, to test for linear increase over time.
adata.obs["stage_continuous"] = adata.obs["stage"].cat.codes
milo.DA_nhoods(adata, design="~stage_continuous")
The differential abundance test results are stored in adata.uns["nhood_adata"].obs. In particular:
logFC: stores the log-Fold Change in abundance (i.e. the slope of the linear model)PValuestores the p-value for the testSpatialFDRstores the p-values adjusted for multiple testing (accounting for overlap between neighbourhoods)
adata.uns["nhood_adata"].obs
| index_cell | kth_distance | SpatialFDR | Nhood_size | logFC | logCPM | F | PValue | FDR | |
|---|---|---|---|---|---|---|---|---|---|
| 0 | cell_42 | 7.738092 | 3.012433e-14 | 60.0 | -1.417459 | 8.863379 | 168.408612 | 7.982954e-16 | 3.086232e-14 |
| 1 | cell_230 | 7.720909 | 3.514147e-14 | 51.0 | -1.415572 | 8.705544 | 180.227447 | 1.097782e-15 | 3.613228e-14 |
| 2 | cell_268 | 8.125346 | 6.421140e-12 | 49.0 | -1.267758 | 8.674349 | 96.595976 | 1.307202e-12 | 6.286541e-12 |
| 3 | cell_401 | 8.443908 | 8.293346e-01 | 83.0 | 0.086342 | 8.831543 | 0.053634 | 8.179472e-01 | 8.309889e-01 |
| 4 | cell_403 | 10.581521 | 5.141152e-02 | 54.0 | 0.396193 | 8.278180 | 4.176706 | 4.709337e-02 | 5.204671e-02 |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 4965 | cell_139212 | 6.854442 | 1.155321e-09 | 94.0 | 1.639116 | 9.259690 | 221.074379 | 3.586851e-10 | 1.126131e-09 |
| 4966 | cell_139272 | 7.441633 | 1.066626e-08 | 60.0 | 1.466970 | 8.819157 | 154.946486 | 3.944226e-09 | 1.042702e-08 |
| 4967 | cell_139296 | 8.785832 | 3.843621e-13 | 83.0 | 1.531593 | 9.031696 | 153.358380 | 4.772253e-14 | 3.894597e-13 |
| 4968 | cell_139297 | 4.096834 | 4.102727e-14 | 120.0 | 1.654067 | 9.407907 | 182.686655 | 1.477024e-15 | 4.243243e-14 |
| 4969 | cell_139304 | 8.789676 | 6.583740e-14 | 97.0 | 1.585345 | 9.199870 | 184.748936 | 3.475374e-15 | 6.720859e-14 |
4970 rows × 9 columns
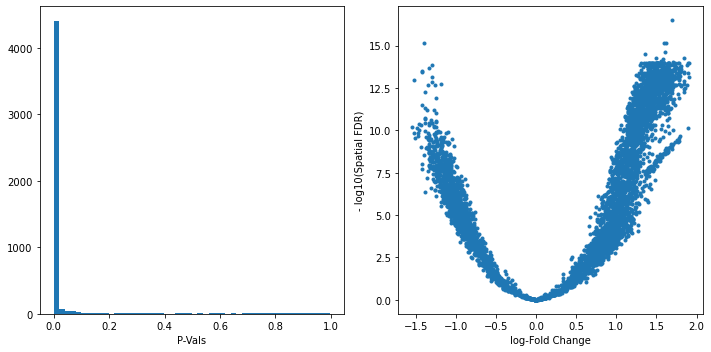
We can start inspecting the results of our DA analysis from a couple of standard diagnostic plots.
old_figsize = plt.rcParams["figure.figsize"]
plt.rcParams["figure.figsize"] = [10,5]
plt.subplot(1,2,1)
plt.hist(adata.uns["nhood_adata"].obs.PValue, bins=50);
plt.xlabel("P-Vals");
plt.subplot(1,2,2)
plt.plot(adata.uns["nhood_adata"].obs.logFC, -np.log10(adata.uns["nhood_adata"].obs.SpatialFDR), '.');
plt.xlabel("log-Fold Change");
plt.ylabel("- log10(Spatial FDR)");
plt.tight_layout()
plt.rcParams["figure.figsize"] = old_figsize
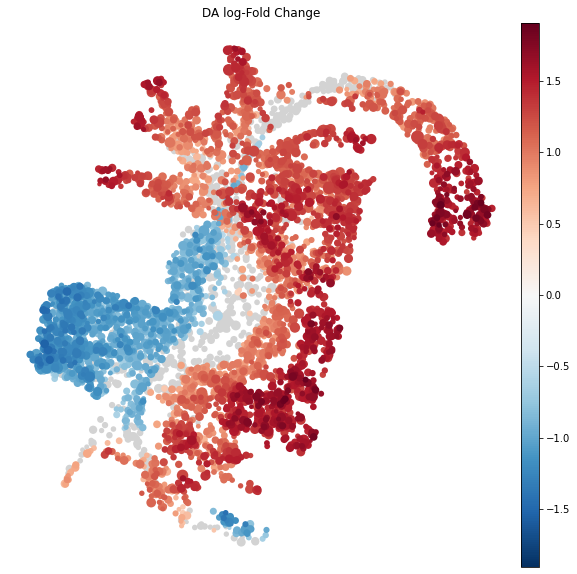
Visualize results on embedding
To visualize DA results relating them to the embedding of single cells, we can build an abstracted graph of neighbourhoods that we can superimpose on the single-cell embedding. Here each node represents a neighbourhood, while edges indicate how many cells two neighbourhoods have in common. Here the layout of nodes is determined by the position of the index cell in the UMAP embedding of all single-cells. The neighbourhoods displaying singificant DA are colored by their log-Fold Change.
import milopy.utils
milopy.utils.build_nhood_graph(adata)
plt.rcParams["figure.figsize"] = [10,10]
milopl.plot_nhood_graph(adata,
alpha=0.01, ## SpatialFDR level (1%)
min_size=2 ## Size of smallest dot
)
Visualize result by celltype
We might want to visualize whether DA is particularly evident in certain cell types. To do this, we assign a cell type label to each neighbourhood by finding the most abundant cell type within cells in each neighbourhood (after all, neighbourhoods are in most cases small subpopulations within the same cell type). We can label neighbourhoods in the results data.frame using the function milopy.core.annotate_nhoods. This also saves the fraction of cells harbouring the label.
milopy.utils.annotate_nhoods(adata, anno_col='celltype')
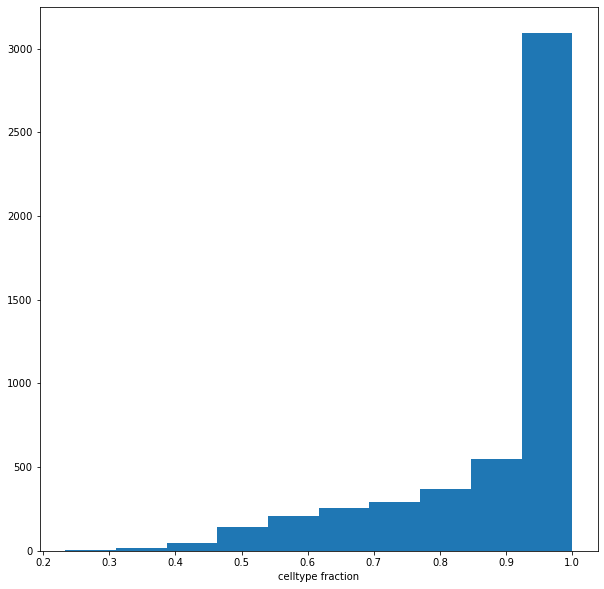
We can see that for the majority of neighbourhoods, almost all cells have the same neighbourhood. We can rename neighbourhoods where less than 60% of the cells have the top label as “Mixed”
plt.hist(adata.uns['nhood_adata'].obs["nhood_annotation_frac"]);
plt.xlabel("celltype fraction")
Text(0.5, 0, 'celltype fraction')
adata.uns['nhood_adata'].obs.loc[adata.uns['nhood_adata'].obs["nhood_annotation_frac"] < 0.6, "nhood_annotation"] = "Mixed"
Now we can plot the fold changes using standard scanpy functions
sc.pl.violin(adata.uns['nhood_adata'], "logFC", groupby="nhood_annotation", rotation=90, show=False);
plt.axhline(y=0, color='black', linestyle='--');
plt.show()
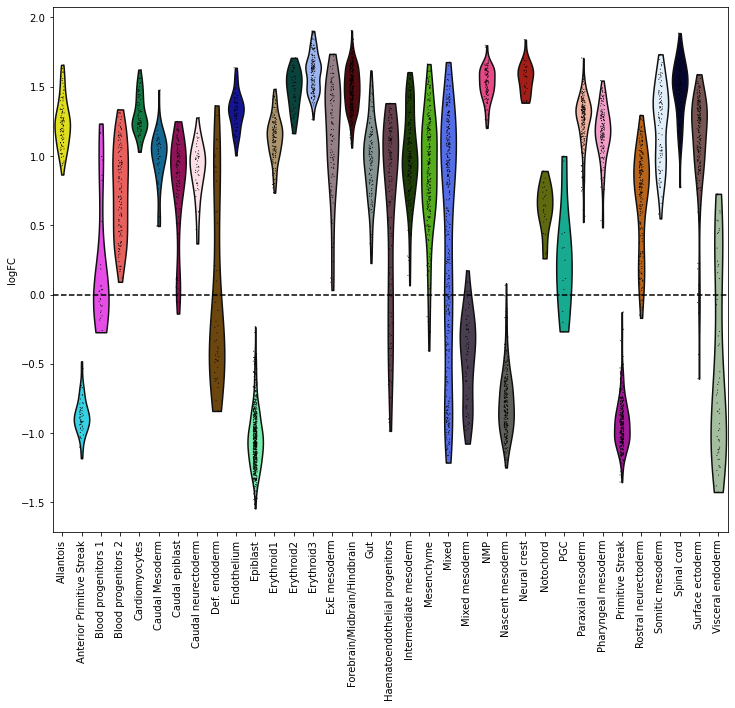
Here this shows that neighbourhoods of cells of the epiblast and primitive streak are enriched in early stages and cells from the neural crest are enriched in later stages.